We provide Analytics as a Service to Departments of Health, who may seek to use data to improve care delivery at the last mile in four key ways
1. To improve data quality amongst community health workers
2. To predict the risk of vulnerable beneficairies
3. To spotlight vulnerable communities
4. To optimize communication interventions to improve health outcomes
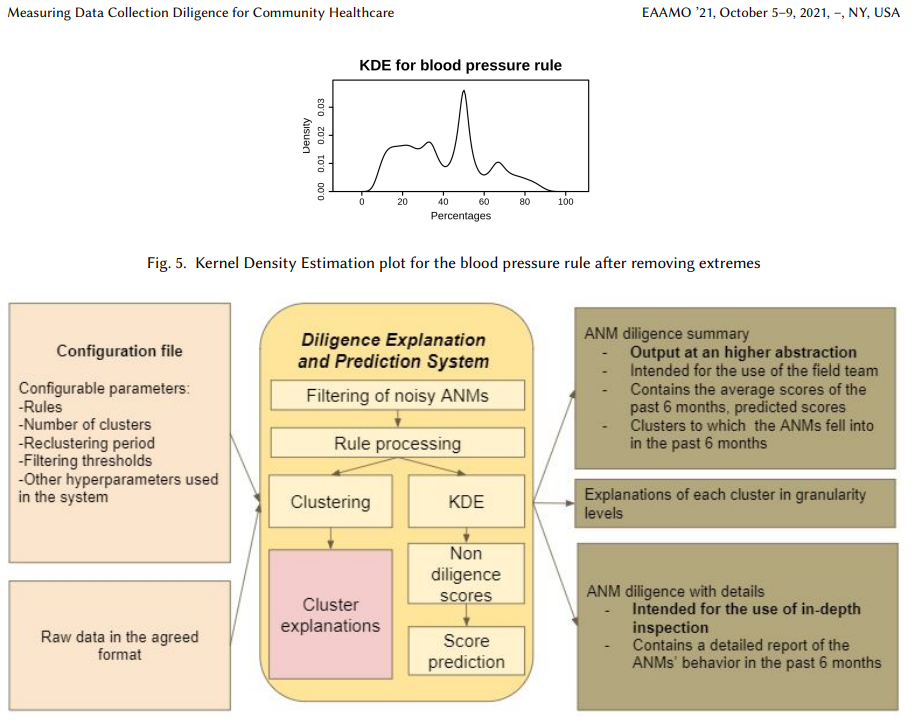
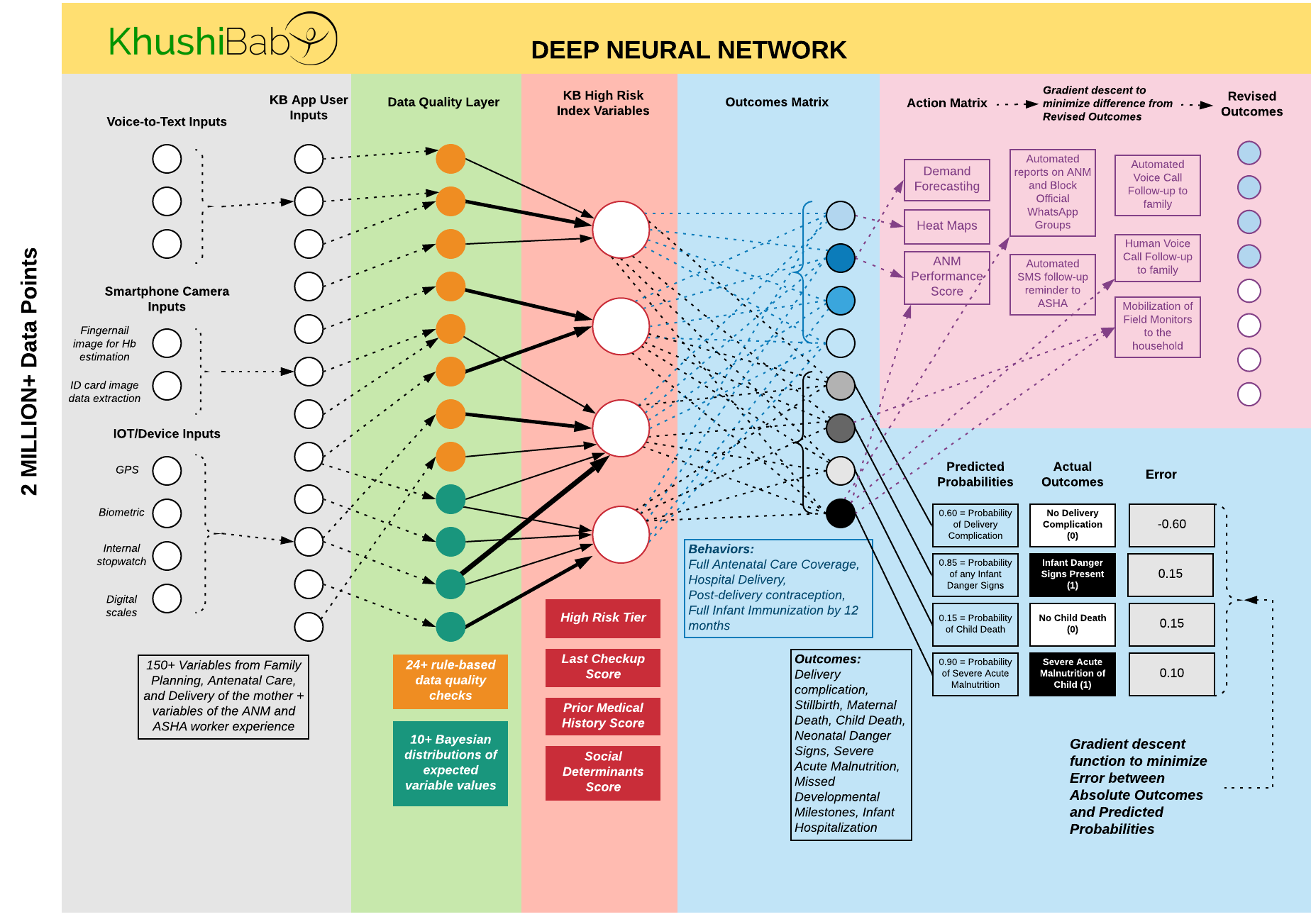
Public health data, whether collected from paper or digitally, vary widely in terms of data quality. There are several ways in which this may manifest. For example, we see discrepancies in reported full infant immunization rates against the individual vaccines components. We see overreporting of normal values, such as normal blood pressures and urine albumin screenings for pregnant women. We see discrepancies between HMIS reported figures and representative sample survey data on key indicators. No two health workers report data in the same way. Multiple factors can lead to data quality issues including: resource constraints faced by the health worker, administrative burden faced by the health worker, lack of intrinsic value of the data reported by the health worker to their routine practice, manual calculation steps, lack of clarity on reporting indicators, incentive schemes that reward positive progress, and lack of supervision on data quality. For this reason, Khushi Baby collaborated with researchers from Google AI for Social Good to create machine-learning models to classify health workers by their data quality phenotype. This score was validated against objective field observations of data reporting practices and was able to detect 84% of diligent health worker behavior. This work has been extended to provide each health worker with a normalized "data diligence" score which can be used by officials to direct supervision and training for poor performers and importantly, to recognize champion health workers with high diligence.
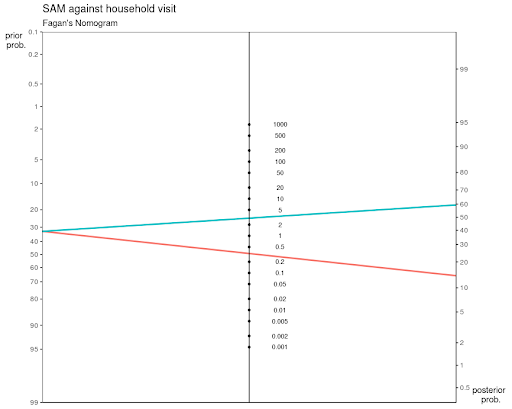
Building off our data diligence score, we have developed machine learning models to predict key maternal and child health outcomes. These Machine-learning models improve predictions of key maternal and child health outcomes including antenatal care dropout, stillbirth, low-birth-weight, severe-underweight-for-age, and severe acute malnutrition. Each model showed strong improvement from pretest to post-test probability of health outcome based on the model’s prediction. Predictions do include chronologically early factors and some non-obvious factors not classically emphasized when performing risk stratification. These predictions can therefore be used to inform early outreach services (e.g. field monitor deployment, mobile medical van deployment) in resource-limited settings and to complement deployments for known high-risk beneficiaries.
One concrete example of how these models come to life can be seen in our outreach efforts to identify malnourished children. After child health visit data is reported through the Khushi Baby mobile application, our Udaipur team works with the local RBSK team to visit the houses of children with z scores less than or equal to -3 for the WHO-based, weight-for-age curves, which classify severe underweight status.
However, when reaching the houses of these suspected malnourished children, only 3 out of every 10 will be malnourished. Now with our machine learning algorithms, we can double the efficiency, identifying 6 severely malnourished children for every 10 houses visited. Higher detection rates leads to higher rates of referrals and treatment completions.
Our AI models to predict individual maternal and child health outcomes have been developed over thousands to tens of thousands of observations and can be accessed here.
Email us at [email protected] for credentials.
In addition to risk stratification models, we are also developing novel image-classification models for moderate anemia during pregnancy, in pregnancy with Wadia Hospital, the largest maternity safety net hospital in Maharashthra, India.
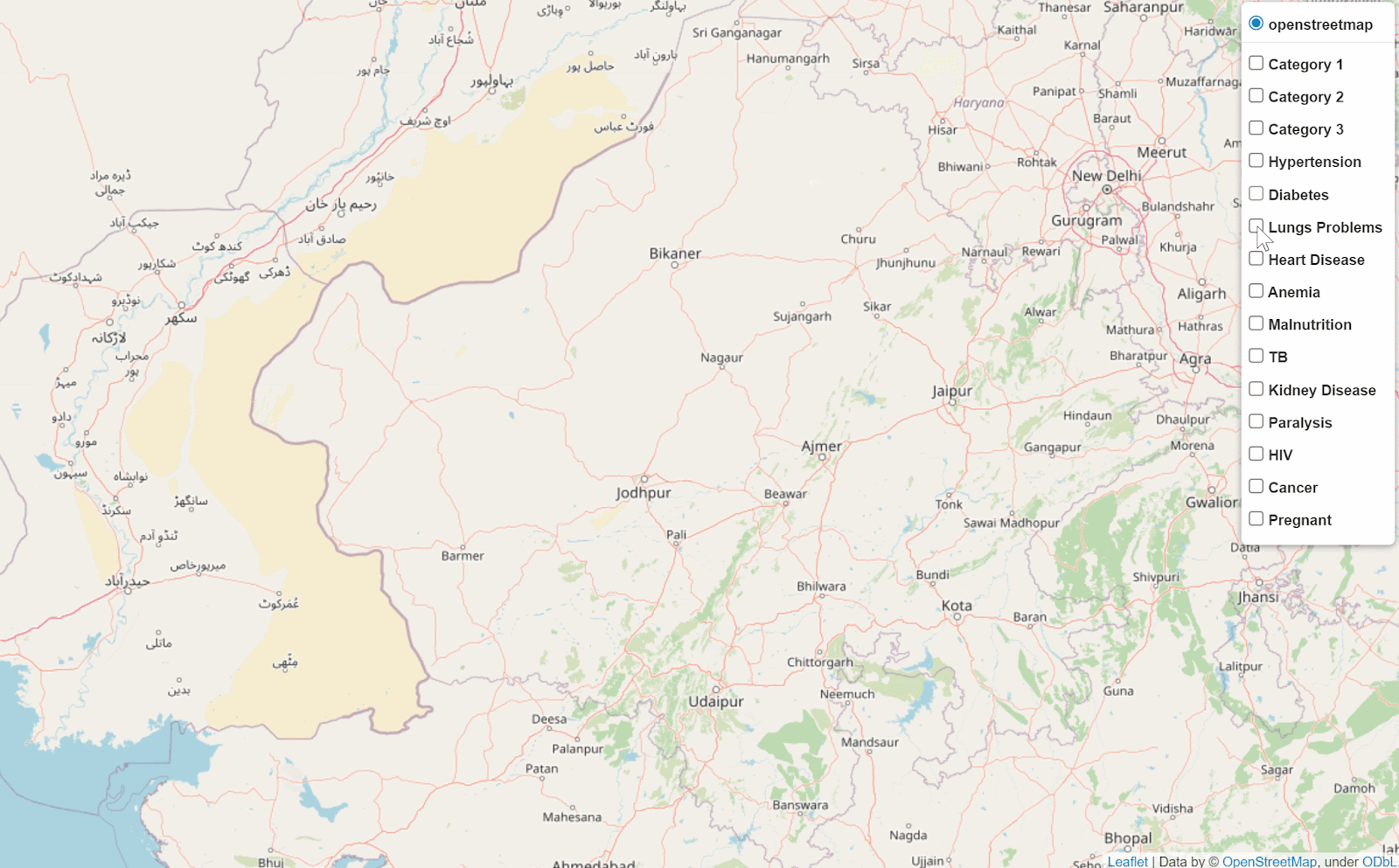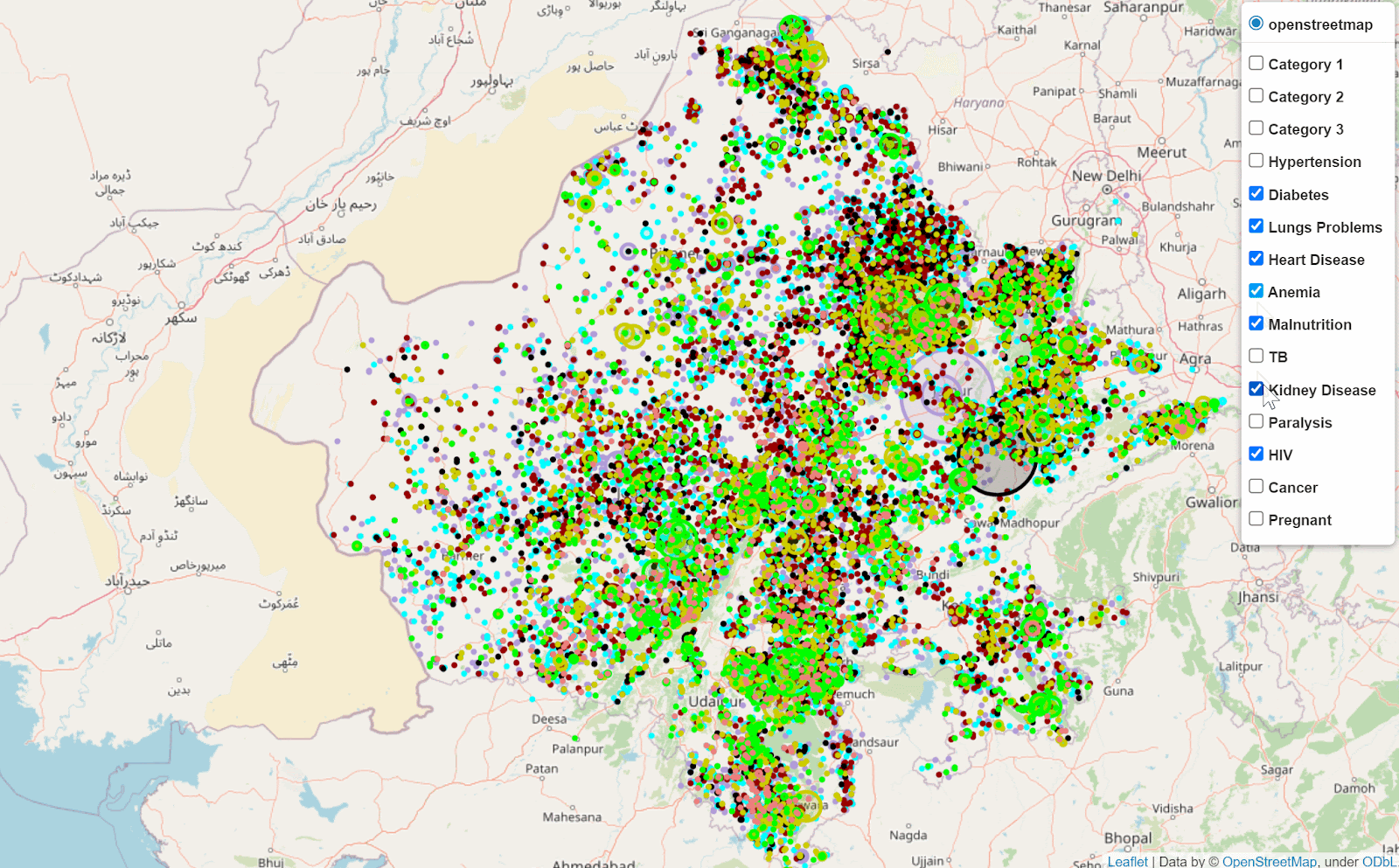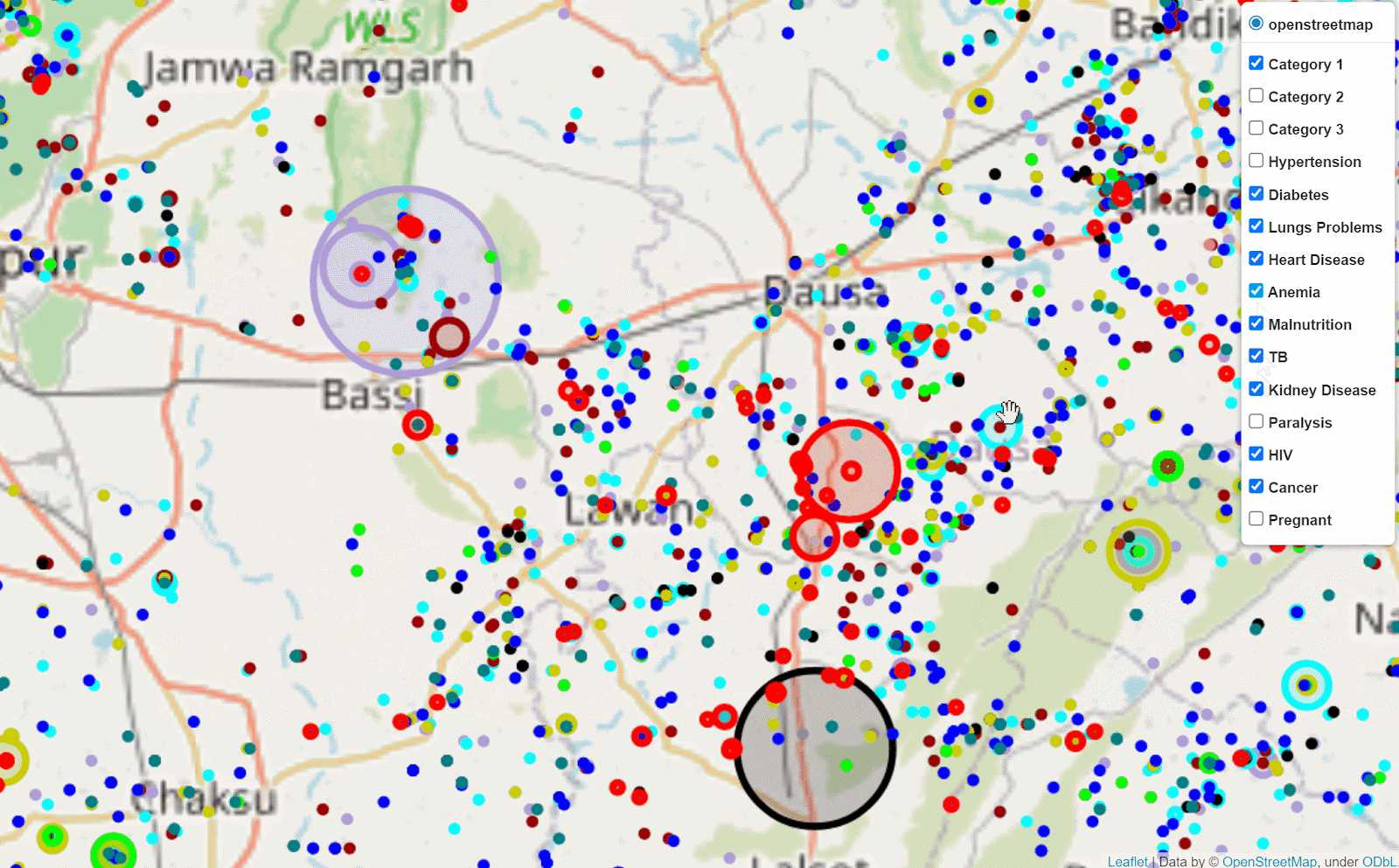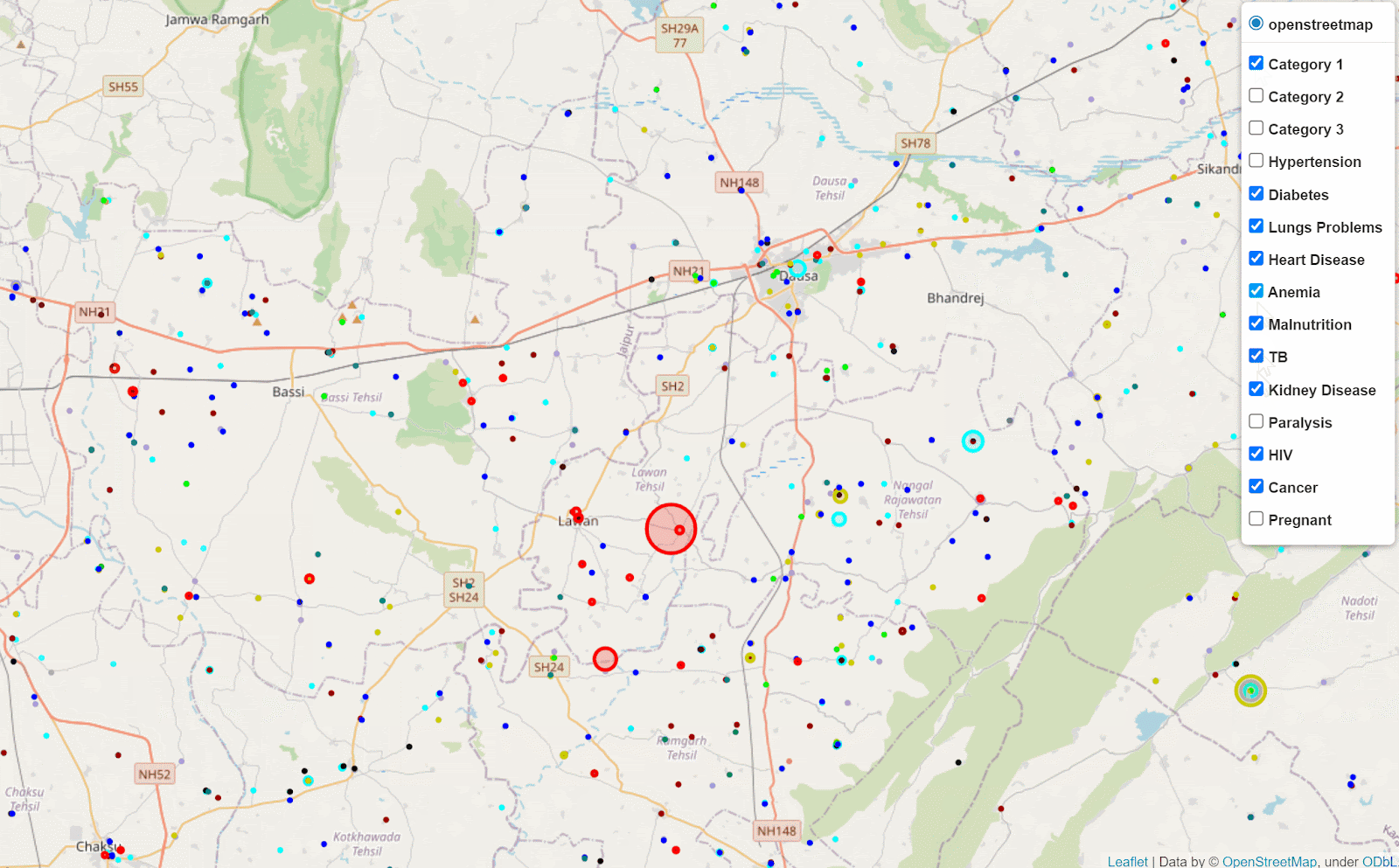
After screening over 14M beneficiaries during the first COVID-19 wave, we were able to use advanced GIS techniques to identify key spatial clusters. We identified spatial outliers, hotspots amongs cold neighborhoods, coldspots amongst hot neighborhoods across disease verticals and for health behaviors. In relation to these identified clusters, targeted camps for further screenings and counseling have been conducted. During the second wave, we focused on identifying data deserts. Most recently we are partnering with the RBSK team to understand how medical van movement corresponds to seasonal spatial variation in malnourish child case detection, and in particular to understand the spatial factors that are associated with higher risk of child malnourishment. For example, we can analyze, after combining several data sets, how rain fall, malaria case reports, maternal tobacco use, and maternal anemia correlate with child malnourishment rates for a given geography.
With over 60,000 health workers on the CHIP platform, and millions of beneficiaries who have contributed contact details, we have the ability to target messaging campaigns and evaluate success on short-term health behavior and data diligence outcomes for beneficiaires and health workers respectivley. We are developing tools to empower health officials to design campaigns, select outcomes of interest, and understand the impact of their scaled intervention. At the same time we are exploring multi-arm bandit approaches to optimize intervention strategy mixes to improve health outcomes.
Our AI for social good work is funded by leading philanthropies: Patrick J. McGovern Foundation, Google.org, and the Trinity Challenge. We collaborate with JHPIEGO on risk models for pregnant women, with support from the Bill and Melinda Gates Foundation. We collaborate with researchers from Singapore Management University, Yale University, Harvard University, and Brown University on various AI projects. To get involved reach us at [email protected].